Besoin de combiner plusieurs fichiers PDF pour n’en faire qu’un seul ? Tout en préservant la confidentialité des fichiers PDF (et donc en évitant les solutions en ligne) ?
Le langage Python peut avantageusement réaliser cette opération de fusion de fichiers. Le propos qui suit va le démontrer avec un script décortiqué pas à pas.
L’exécutable du programme est proposé en libre téléchargement en pied d’article.
Fonctionnement général du script :
Dans un premier temps, le programme demande à l’utilisateur de saisir le nom du fichier PDF qui résultera de la fusion des PDF.

Cette action est réalisée à l’aide de l’instruction Input :
pdf_fusionne = input ("Saisissez le nom du fichier PDF à générer : ")
pdf_fusionne = input ("Saisissez le nom du fichier PDF à générer : ")
pdf_fusionne = input ("Saisissez le nom du fichier PDF à générer : ")
Le nom du fichier est stocké dans la variable pdf_fusionne.
Le script ajoute l’extension .pdf à la variable pdf_fusionne si l’utilisateur ne l’a pas saisie :
if pdf_fusionne[-4:]!=".pdf":
pdf_fusionne=pdf_fusionne + ".pdf"
if pdf_fusionne[-4:]!=".pdf":
pdf_fusionne=pdf_fusionne + ".pdf"
if pdf_fusionne[-4:]!=".pdf":
pdf_fusionne=pdf_fusionne + ".pdf"
Ce test est réalisé grâce à la structure conditionnelle if… elif… else et à l’utilisation aux opérateurs de l’arithmétique booléenne :
| Opérateur |
Définition |
| == |
Permet de tester l’égalité entre deux valeurs |
| != |
Permet de tester la différence entre deux valeurs |
| < |
Permet de tester si une valeur est strictement inférieure à une autre |
| > |
Permet de tester si une valeur est strictement supérieure à une autre |
| <= |
Permet de tester si une valeur est inférieure ou égale à une autre |
| >= |
Permet de tester si une valeur est supérieure ou égale à une autre |
L’utilisateur est ensuite invité à sélectionner le dossier contenant les fichiers PDF à combiner :
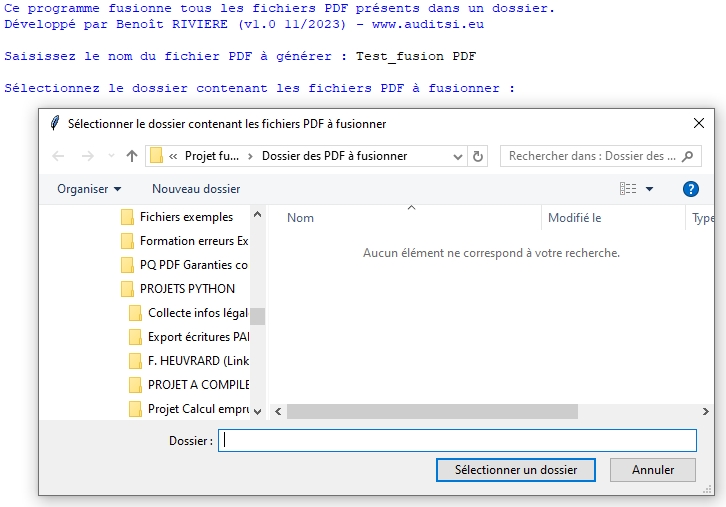
Le nom du dossier sélectionné (fonction diropenbox) est stocké dans la variable chemin_PDF :
# Boîte de dialogue de sélection d'un dossier de fichiers PDF
chemin_PDF = easygui.diropenbox(title="Sélectionner le dossier contenant les fichiers PDF à fusionner", default=chemin_PDF)
# Boîte de dialogue de sélection d'un dossier de fichiers PDF
chemin_PDF = easygui.diropenbox(title="Sélectionner le dossier contenant les fichiers PDF à fusionner", default=chemin_PDF)
# Boîte de dialogue de sélection d'un dossier de fichiers PDF
chemin_PDF = easygui.diropenbox(title="Sélectionner le dossier contenant les fichiers PDF à fusionner", default=chemin_PDF)
Le script appelle la fonction collecte_fichiers_pdf qui liste tous les fichiers PDF contenu dans le dossier sélectionné par l’utilisateur.
# Appel de la fonction liste_fichiers_pdf
liste_fichiers_pdf = collecte_liste_fichiers_pdf(chemin_PDF)
# Appel de la fonction liste_fichiers_pdf
liste_fichiers_pdf = collecte_liste_fichiers_pdf(chemin_PDF)
# Appel de la fonction liste_fichiers_pdf
liste_fichiers_pdf = collecte_liste_fichiers_pdf(chemin_PDF)
Cette fonction passe en revue tous les fichiers à l’aide d’une boucle compteur (for nom_fichier_en_cours in os.listdir(dossier):) et ne retient que les fichiers PDF (nom_fichier_en_cours.lower().endswith(‘.pdf’):).
Le programme affiche progressivement les fichiers retenus (ou non) :

C’est la commande print() qui permet l’affichage du texte.
print("Liste des fichiers PDF inclus dans la fusion :")
print("-" * 85)
print("Liste des fichiers PDF inclus dans la fusion :")
print()
print("-" * 85)
print("Liste des fichiers PDF inclus dans la fusion :")
print()
La commande print(“-” * 85) permet de dessiner une ligne en répétant 85 fois l’affichage du signe moins. Rudimentaire mais efficace.
La tabulation est introduite devant les libellés “Nombre de pages” et Auteur du document” par la séquence d’échappement \t :
print(f"\tNombre de pages : {pages}")
print(f"\tNombre de pages : {pages}")
print(f"\tNombre de pages : {pages}")
Les opérations de fusion de fichiers PDF sont réalisées à l’aide de l’objet merger créé spécialement à l’aide de PyPDF2.PdfMerger(), de la boucle for pdf_en_cours in liste_fichiers_pdf: qui ajoute tour à tour tous les fichiers PDF (merger.append(chemin_PDF + pdf_en_cours) dans l’instance de fusion). Enfin, merger.write(chemin_projet + pdf_fusionne) fusionne les fichiers présents dans l’instance et merger.close() clôture le fichier PDF rendu ainsi accessible à l’utilisateur.
# Création d'un objet merger (fusion)
merger = PyPDF2.PdfMerger()
# Boucle sur la liste des fichiers à fusionner
for pdf_en_cours in liste_fichiers_pdf:
# Ajout du PDF à la chaîne de fusion
merger.append(chemin_PDF + pdf_en_cours)
# Fusion des fichiers et fermeture de l'objet
merger.write(chemin_projet + pdf_fusionne)
# Création d'un objet merger (fusion)
merger = PyPDF2.PdfMerger()
[...]
# Boucle sur la liste des fichiers à fusionner
for pdf_en_cours in liste_fichiers_pdf:
[...]
# Ajout du PDF à la chaîne de fusion
merger.append(chemin_PDF + pdf_en_cours)
# Fusion des fichiers et fermeture de l'objet
merger.write(chemin_projet + pdf_fusionne)
merger.close()
# Création d'un objet merger (fusion)
merger = PyPDF2.PdfMerger()
[...]
# Boucle sur la liste des fichiers à fusionner
for pdf_en_cours in liste_fichiers_pdf:
[...]
# Ajout du PDF à la chaîne de fusion
merger.append(chemin_PDF + pdf_en_cours)
# Fusion des fichiers et fermeture de l'objet
merger.write(chemin_projet + pdf_fusionne)
merger.close()
Enfin, le programme affiche le message “Traitement terminé” indiquant que les opérations sont achevées :

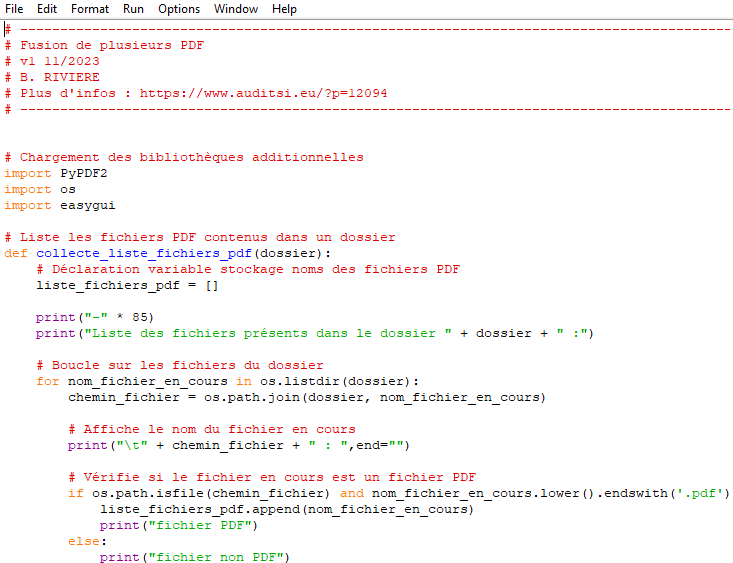
Script complet du projet :
# -------------------------------------------------------------------------------------------
# Fusion de plusieurs PDF
# Plus d'infos : https://www.auditsi.eu/?p=12094
# -------------------------------------------------------------------------------------------
# Chargement des bibliothèques additionnelles
# Liste les fichiers PDF contenus dans un dossier
def collecte_liste_fichiers_pdf(dossier):
# Déclaration variable stockage noms des fichiers PDF
print("Liste des fichiers présents dans le dossier " + dossier + " :")
# Boucle sur les fichiers du dossier
for nom_fichier_en_cours in os.listdir(dossier):
chemin_fichier = os.path.join(dossier, nom_fichier_en_cours)
# Affiche le nom du fichier en cours
print("\t" + chemin_fichier + " : ",end="")
# Vérifie si le fichier en cours est un fichier PDF
if os.path.isfile(chemin_fichier) and nom_fichier_en_cours.lower().endswith('.pdf'):
liste_fichiers_pdf.append(nom_fichier_en_cours)
return liste_fichiers_pdf
# Collecte des informations d'un fichier PDF
def collecte_infos_pdf(chemin_fichier):
# Ouverture du fichier PDF en mode binaire
with open(chemin_fichier, 'rb') as fichier_pdf:
# Création d'un objet PdfReader
lecteur_pdf = PyPDF2.PdfReader(fichier_pdf)
# Lecture nombre de pages
nombre_pages =len(lecteur_pdf.pages)
# Obtention des métadonnées du document
metadonnees = lecteur_pdf.metadata
# Extraction du nom de l'auteur du PDF (s'il est disponible)
auteur = "Auteur non spécifié" # Valeur par défaut
if metadonnees is not None and metadonnees.get('/Author'):
auteur = metadonnees.author
return nombre_pages, auteur
print("Ce programme fusionne tous les fichiers PDF présents dans un dossier.")
print("Développé par Benoît RIVIERE (v1.0 11/2023) - www.auditsi.eu")
# Obtention du nom du document PDF fusionné
pdf_fusionne = input ("Saisissez le nom du fichier PDF à générer : ")
pdf_fusionne = "PDF fusionné"
if pdf_fusionne[-4:]!=".pdf":
pdf_fusionne=pdf_fusionne + ".pdf"
# Chemin d'accès au projet
chemin_projet = os.getcwd() + '\\'
# Chemin d'accès par défaut aux fichiers PDF à fusionner
chemin_PDF = chemin_projet + 'Dossier des PDF à fusionner'
print("Sélectionnez le dossier contenant les fichiers PDF à fusionner :")
# Boîte de dialogue de sélection d'un dossier de fichiers PDF
chemin_PDF = easygui.diropenbox(title="Sélectionner le dossier contenant les fichiers PDF à fusionner", default=chemin_PDF)
chemin_PDF = chemin_PDF + "\\"
# Affichage du nom du dossier sélectionné
print("Dossier sélectionné :", chemin_PDF)
# Appel de la fonction liste_fichiers_pdf
liste_fichiers_pdf = collecte_liste_fichiers_pdf(chemin_PDF)
# Création d'un objet merger (fusion)
merger = PyPDF2.PdfMerger()
print("Liste des fichiers PDF inclus dans la fusion :")
# Boucle sur la liste des fichiers à fusionner
for pdf_en_cours in liste_fichiers_pdf:
# Appel de la fonction collecte_infos_pdf
pages, auteur = collecte_infos_pdf(chemin_PDF + pdf_en_cours)
print("Information du fichier : " + pdf_en_cours)
print(f"\tNombre de pages : {pages}")
print(f"\tAuteur du document : {auteur}")
# Ajout du PDF à la chaîne de fusion
merger.append(chemin_PDF + pdf_en_cours)
# Fusion des fichiers et fermeture de l'objet
merger.write(chemin_projet + pdf_fusionne)
# Appel de la fonction collecte_infos_pdf
pages, auteur = collecte_infos_pdf(chemin_projet + pdf_fusionne)
# Affichage des infos du PDF fusionné
print("Information du fichier PDF fusionné : " + pdf_fusionne)
print(f"\tNombre de pages : {pages}")
print(f"\tAuteur du document : {auteur}")
print("Traitement terminé")
# -------------------------------------------------------------------------------------------
# Fusion de plusieurs PDF
# v1 11/2023
# B. RIVIERE
# Plus d'infos : https://www.auditsi.eu/?p=12094
# -------------------------------------------------------------------------------------------
# Chargement des bibliothèques additionnelles
import PyPDF2
import os
import easygui
# Liste les fichiers PDF contenus dans un dossier
def collecte_liste_fichiers_pdf(dossier):
# Déclaration variable stockage noms des fichiers PDF
liste_fichiers_pdf = []
print("-" * 85)
print("Liste des fichiers présents dans le dossier " + dossier + " :")
# Boucle sur les fichiers du dossier
for nom_fichier_en_cours in os.listdir(dossier):
chemin_fichier = os.path.join(dossier, nom_fichier_en_cours)
# Affiche le nom du fichier en cours
print("\t" + chemin_fichier + " : ",end="")
# Vérifie si le fichier en cours est un fichier PDF
if os.path.isfile(chemin_fichier) and nom_fichier_en_cours.lower().endswith('.pdf'):
liste_fichiers_pdf.append(nom_fichier_en_cours)
print("fichier PDF")
else:
print("fichier non PDF")
print()
return liste_fichiers_pdf
# Collecte des informations d'un fichier PDF
def collecte_infos_pdf(chemin_fichier):
# Ouverture du fichier PDF en mode binaire
with open(chemin_fichier, 'rb') as fichier_pdf:
# Création d'un objet PdfReader
lecteur_pdf = PyPDF2.PdfReader(fichier_pdf)
# Lecture nombre de pages
nombre_pages =len(lecteur_pdf.pages)
# Obtention des métadonnées du document
metadonnees = lecteur_pdf.metadata
# Extraction du nom de l'auteur du PDF (s'il est disponible)
auteur = "Auteur non spécifié" # Valeur par défaut
if metadonnees is not None and metadonnees.get('/Author'):
auteur = metadonnees.author
return nombre_pages, auteur
print("-" * 85)
print("Ce programme fusionne tous les fichiers PDF présents dans un dossier.")
print("Développé par Benoît RIVIERE (v1.0 11/2023) - www.auditsi.eu")
print()
# Obtention du nom du document PDF fusionné
pdf_fusionne = input ("Saisissez le nom du fichier PDF à générer : ")
if pdf_fusionne=="":
pdf_fusionne = "PDF fusionné"
if pdf_fusionne[-4:]!=".pdf":
pdf_fusionne=pdf_fusionne + ".pdf"
print()
# Chemin d'accès au projet
chemin_projet = os.getcwd() + '\\'
# Chemin d'accès par défaut aux fichiers PDF à fusionner
chemin_PDF = chemin_projet + 'Dossier des PDF à fusionner'
#
print("Sélectionnez le dossier contenant les fichiers PDF à fusionner :")
# Boîte de dialogue de sélection d'un dossier de fichiers PDF
chemin_PDF = easygui.diropenbox(title="Sélectionner le dossier contenant les fichiers PDF à fusionner", default=chemin_PDF)
chemin_PDF = chemin_PDF + "\\"
# Affichage du nom du dossier sélectionné
print("Dossier sélectionné :", chemin_PDF)
print()
# Appel de la fonction liste_fichiers_pdf
liste_fichiers_pdf = collecte_liste_fichiers_pdf(chemin_PDF)
# Création d'un objet merger (fusion)
merger = PyPDF2.PdfMerger()
print("-" * 85)
print("Liste des fichiers PDF inclus dans la fusion :")
print()
# Boucle sur la liste des fichiers à fusionner
for pdf_en_cours in liste_fichiers_pdf:
# Appel de la fonction collecte_infos_pdf
pages, auteur = collecte_infos_pdf(chemin_PDF + pdf_en_cours)
# Affichage des infos
print("Information du fichier : " + pdf_en_cours)
print(f"\tNombre de pages : {pages}")
print(f"\tAuteur du document : {auteur}")
print()
# Ajout du PDF à la chaîne de fusion
merger.append(chemin_PDF + pdf_en_cours)
# Fusion des fichiers et fermeture de l'objet
merger.write(chemin_projet + pdf_fusionne)
merger.close()
# Appel de la fonction collecte_infos_pdf
pages, auteur = collecte_infos_pdf(chemin_projet + pdf_fusionne)
# Affichage des infos du PDF fusionné
print("-" * 85)
print("Information du fichier PDF fusionné : " + pdf_fusionne)
print(f"\tNombre de pages : {pages}")
print(f"\tAuteur du document : {auteur}")
print()
print("Traitement terminé")
# -------------------------------------------------------------------------------------------
# Fusion de plusieurs PDF
# v1 11/2023
# B. RIVIERE
# Plus d'infos : https://www.auditsi.eu/?p=12094
# -------------------------------------------------------------------------------------------
# Chargement des bibliothèques additionnelles
import PyPDF2
import os
import easygui
# Liste les fichiers PDF contenus dans un dossier
def collecte_liste_fichiers_pdf(dossier):
# Déclaration variable stockage noms des fichiers PDF
liste_fichiers_pdf = []
print("-" * 85)
print("Liste des fichiers présents dans le dossier " + dossier + " :")
# Boucle sur les fichiers du dossier
for nom_fichier_en_cours in os.listdir(dossier):
chemin_fichier = os.path.join(dossier, nom_fichier_en_cours)
# Affiche le nom du fichier en cours
print("\t" + chemin_fichier + " : ",end="")
# Vérifie si le fichier en cours est un fichier PDF
if os.path.isfile(chemin_fichier) and nom_fichier_en_cours.lower().endswith('.pdf'):
liste_fichiers_pdf.append(nom_fichier_en_cours)
print("fichier PDF")
else:
print("fichier non PDF")
print()
return liste_fichiers_pdf
# Collecte des informations d'un fichier PDF
def collecte_infos_pdf(chemin_fichier):
# Ouverture du fichier PDF en mode binaire
with open(chemin_fichier, 'rb') as fichier_pdf:
# Création d'un objet PdfReader
lecteur_pdf = PyPDF2.PdfReader(fichier_pdf)
# Lecture nombre de pages
nombre_pages =len(lecteur_pdf.pages)
# Obtention des métadonnées du document
metadonnees = lecteur_pdf.metadata
# Extraction du nom de l'auteur du PDF (s'il est disponible)
auteur = "Auteur non spécifié" # Valeur par défaut
if metadonnees is not None and metadonnees.get('/Author'):
auteur = metadonnees.author
return nombre_pages, auteur
print("-" * 85)
print("Ce programme fusionne tous les fichiers PDF présents dans un dossier.")
print("Développé par Benoît RIVIERE (v1.0 11/2023) - www.auditsi.eu")
print()
# Obtention du nom du document PDF fusionné
pdf_fusionne = input ("Saisissez le nom du fichier PDF à générer : ")
if pdf_fusionne=="":
pdf_fusionne = "PDF fusionné"
if pdf_fusionne[-4:]!=".pdf":
pdf_fusionne=pdf_fusionne + ".pdf"
print()
# Chemin d'accès au projet
chemin_projet = os.getcwd() + '\\'
# Chemin d'accès par défaut aux fichiers PDF à fusionner
chemin_PDF = chemin_projet + 'Dossier des PDF à fusionner'
#
print("Sélectionnez le dossier contenant les fichiers PDF à fusionner :")
# Boîte de dialogue de sélection d'un dossier de fichiers PDF
chemin_PDF = easygui.diropenbox(title="Sélectionner le dossier contenant les fichiers PDF à fusionner", default=chemin_PDF)
chemin_PDF = chemin_PDF + "\\"
# Affichage du nom du dossier sélectionné
print("Dossier sélectionné :", chemin_PDF)
print()
# Appel de la fonction liste_fichiers_pdf
liste_fichiers_pdf = collecte_liste_fichiers_pdf(chemin_PDF)
# Création d'un objet merger (fusion)
merger = PyPDF2.PdfMerger()
print("-" * 85)
print("Liste des fichiers PDF inclus dans la fusion :")
print()
# Boucle sur la liste des fichiers à fusionner
for pdf_en_cours in liste_fichiers_pdf:
# Appel de la fonction collecte_infos_pdf
pages, auteur = collecte_infos_pdf(chemin_PDF + pdf_en_cours)
# Affichage des infos
print("Information du fichier : " + pdf_en_cours)
print(f"\tNombre de pages : {pages}")
print(f"\tAuteur du document : {auteur}")
print()
# Ajout du PDF à la chaîne de fusion
merger.append(chemin_PDF + pdf_en_cours)
# Fusion des fichiers et fermeture de l'objet
merger.write(chemin_projet + pdf_fusionne)
merger.close()
# Appel de la fonction collecte_infos_pdf
pages, auteur = collecte_infos_pdf(chemin_projet + pdf_fusionne)
# Affichage des infos du PDF fusionné
print("-" * 85)
print("Information du fichier PDF fusionné : " + pdf_fusionne)
print(f"\tNombre de pages : {pages}")
print(f"\tAuteur du document : {auteur}")
print()
print("Traitement terminé")
J’ai rédigé ce script avec l’aide de ChatGPT. Cet outil est une aide appréciable pour apprendre, pour aller plus vite, gagner en productivité. A ce sujet, ChatGPT peut analyser le contenu de fichiers pour nous, à l’image d’une photo :

Bluffant, non ? Qui de mieux que ChatGPT pour parler de chat ? 
Tous les articles en rapport avec le langage Python / les fichiers PDF
___
Pour approfondir le sujet : se former à la programmation en langage Python pour automatiser ses tâches
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
2.13.0.0
Fusion De Plusieurs PDF : exécutable à dézipper
| Auteur: | Benoît RIVIERE |
| Date: | mardi 23 juillet 2024 |
The following two tabs change content below.




